Sentiment analysis on 1.6M tweets with comparison of NLP models (TF-IDF, CNN, LSTM, DistilBERT), full MLOps workflow, cloud API, and CI/CD deployment.
Stack
Project links
Project Context and Objectives
The goal of this project was to build a functional Artificial Intelligence prototype capable of accurately predicting the sentiment (positive or negative) expressed in English-language tweets. Since no internal dataset was available, the project relied on a large open-source dataset containing approximately 1.6 million tweets labeled with binary sentiments (positive and negative). The final objective was to develop a high-performing model, accessible through a cloud API and usable through an intuitive web interface.
MLOps Principles
Another key objective was to align the project, as much as possible, with the core principles of MLOps.
1. ML Lifecycle Automation
All stages of the machine learning lifecycle, from data exploration to deployment, including training and monitoring, should be automated and orchestrated.
This includes data collection, preparation, training, testing, deployment, monitoring, and maintenance.
As shown later, all of this was managed through MLflow and GitHub.
2. Continuous Integration and Continuous Deployment (CI/CD)
MLOps adapts DevOps practices to machine learning by emphasizing continuous integration (automated testing, code and data validation) and continuous deployment (fast and reliable production releases).
This was mainly handled through GitHub Actions, as well as DockerHub and Azure.
3. Version Management
The goal was to version not only the code, but also the data, models, and configurations to guarantee reproducibility and track project evolution (experiments, deployed models, datasets used).
This was managed through MLflow and GitHub.
4. Monitoring and Traceability
Tools were implemented to monitor production model performance (accuracy, data drift, concept drift).
Model traceability ensures knowing at any time which model is deployed, with which data, and how it was trained.
Alerts were managed through Azure Insights, while traceability relied on GitHub and MLflow.
5. Cross-Functional Collaboration
Facilitating collaboration between data scientists, ML engineers, developers, and IT operations teams.
Using centralized platforms, shared pipelines, and common environment management.
6. Scalability and Reproducibility
Making ML pipelines scalable (able to handle large data volumes) and reproducible (same results with the same inputs, ability to rerun an experiment identically).
7. Security and Compliance
Ensuring data and model security, as well as regulatory compliance (access management, logs, auditing).
Data Preparation and Exploration
The initial data included not only tweet texts, but also metadata such as user identifiers and publication dates.

The first step in this type of project is to inspect and validate the data in order to identify anomalies or labeling errors. I quickly detected identical tweets classified inconsistently, as shown in the examples below:
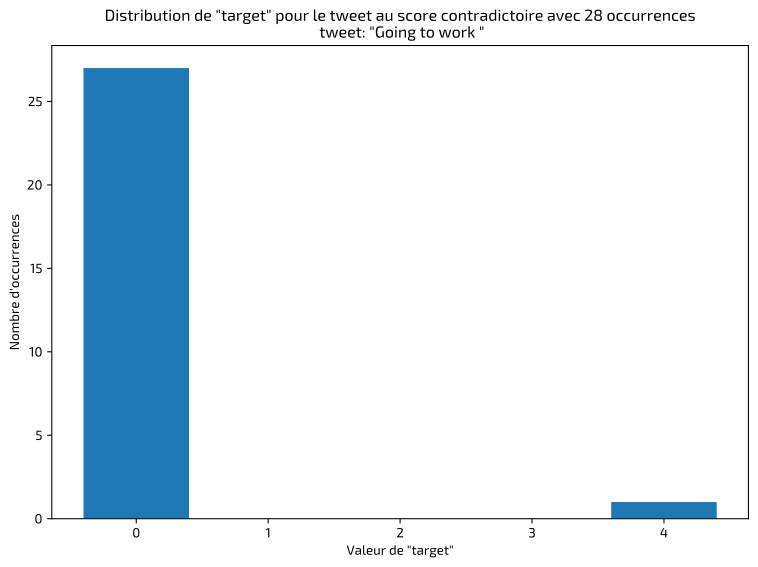
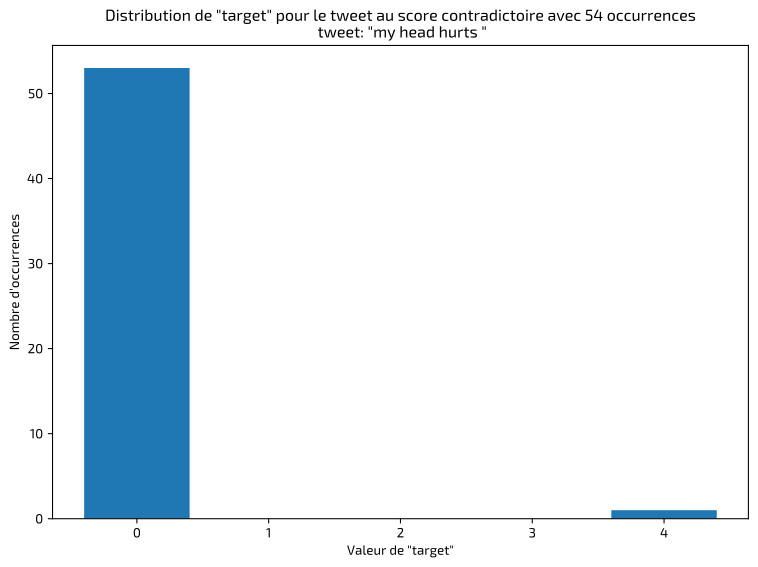
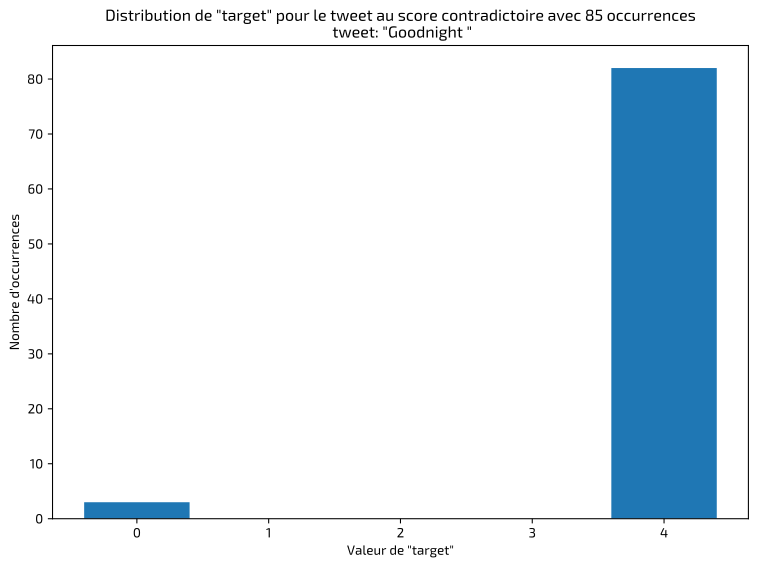
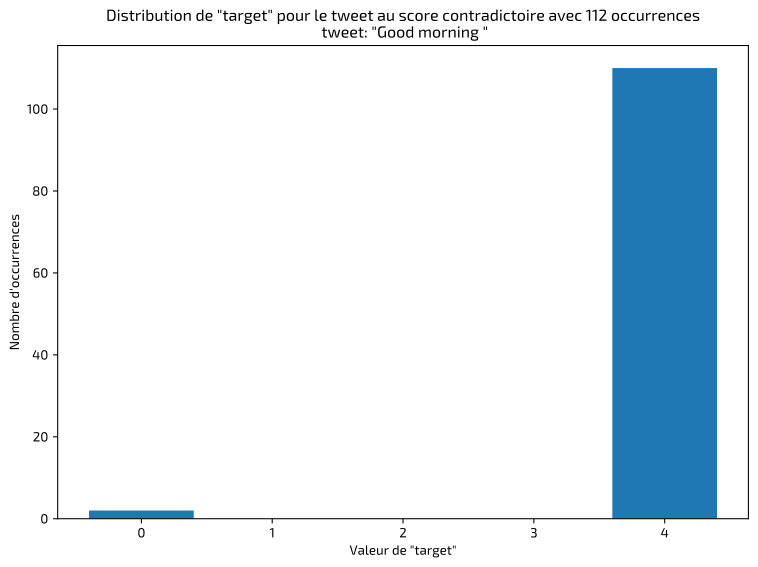
In these cases, I kept the majority label. The final result shows a balanced dataset between positive and negative classes:
Models Evaluated
Several approaches were methodically explored to identify the most effective solution for this specific problem.
Hyperparameter Search
When training an AI model, there are parameters called hyperparameters. These are external settings of the model, such as batch size, learning rate, or number of epochs.
Hyperparameters are not learned by the model itself: they must be chosen before training, and their values can strongly impact final performance.
Grid search is a systematic method used to find the best hyperparameter combination.
Evaluation Criteria and Methods
Model performance was evaluated using several rigorous metrics:
Accuracy: Percentage of correct predictions across all outputs. Reliable here thanks to the balanced dataset. This was the main metric used for hyperparameter selection.
F1-score: Balances the ability to detect positive cases while limiting false positives.
ROC AUC: Measures the model’s ability to rank predictions correctly according to probability.
Inference time: A practical indicator of model complexity and operational cost.
Data Preprocessing and Vocabulary Selection
Several preprocessing strategies were explored, from basic cleaning (removing URLs, hashtags, mentions) to more advanced methods (lemmatization, tokenization with spaCy). Particular attention was given to vocabulary size selection in order to efficiently cover the corpus while limiting noise and unnecessary complexity.
Model Types
Traditional Model (Logistic Regression + TF-IDF)
This classical approach relies on two main steps: TF-IDF vectorization of tweets, which weights words according to their frequency within documents and rarity across the corpus, followed by logistic regression for binary sentiment classification.
Hyperparameter search focused mainly on minimum and maximum document frequency thresholds, n-gram range, and regularization strength (C) to reduce overfitting.
Convolutional Neural Network (CNN)
The CNN approach stands out through its ability to detect patterns in textual data. The model uses an embedding layer to transform words into vectors, followed by two Conv1D layers to capture sentiment-related expressions. A global max pooling layer summarizes detected patterns before dense output layers generate the final prediction.
Pretrained Embeddings
While the network initially learned its own embeddings, I also tested two pretrained embeddings to leverage existing semantic knowledge:
- GloVe Twitter: specifically designed to capture the linguistic characteristics of social media.
- GoogleNews Word2Vec: more general-purpose, strong on broad vocabulary but less adapted to informal tweet language.
Critical hyperparameters included embedding dimension, number of filters, kernel size, dropout rate, learning rate, and batch size.
Recurrent Neural Network (RNN – Bidirectional LSTM)
The bidirectional LSTM architecture is particularly suited for contextual sentence analysis, as it processes both preceding and following context around each word. Two bidirectional layers were used to extract and consolidate contextual information required for accurate classification.
Hyperparameters included the number of LSTM units, learning rate, and batch size.
Transformer Model (DistilBERT)
DistilBERT, a compact and optimized version of BERT, uses an attention mechanism to capture nuance and long-range dependencies in text. This model, particularly strong on informal language, was fine-tuned specifically for this dataset.
The main optimized hyperparameters were learning rate and batch size.
Professional Use of MLflow with DagsHub
I used MLflow, through the DagsHub platform, to systematically track all experiments:
- Automatic logging of training parameters, metrics, and results.
- Fast and accurate comparison of models and runs.
- Improved reproducibility and experiment traceability.
Performance Comparison and Final Model Selection
Here is the performance comparison across experiments:
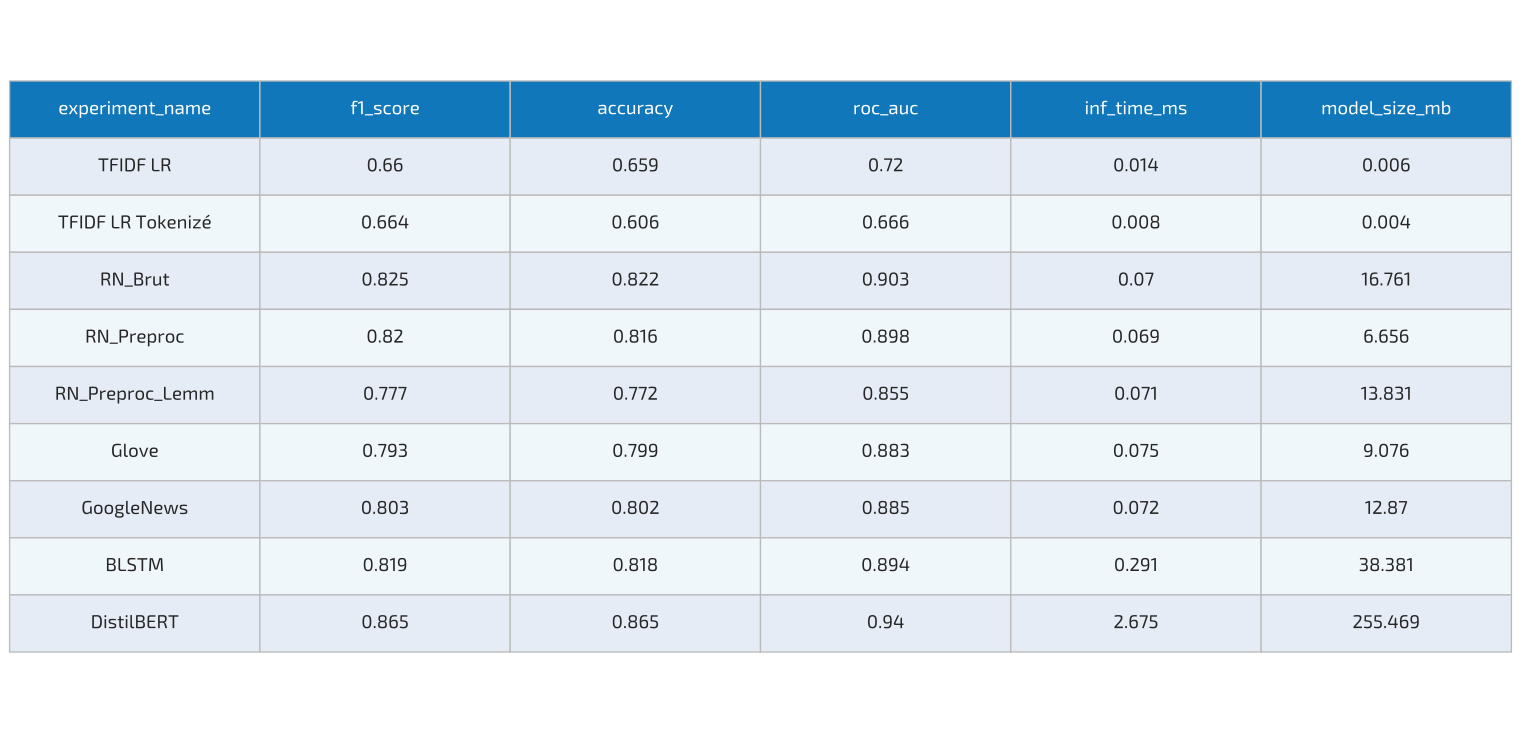
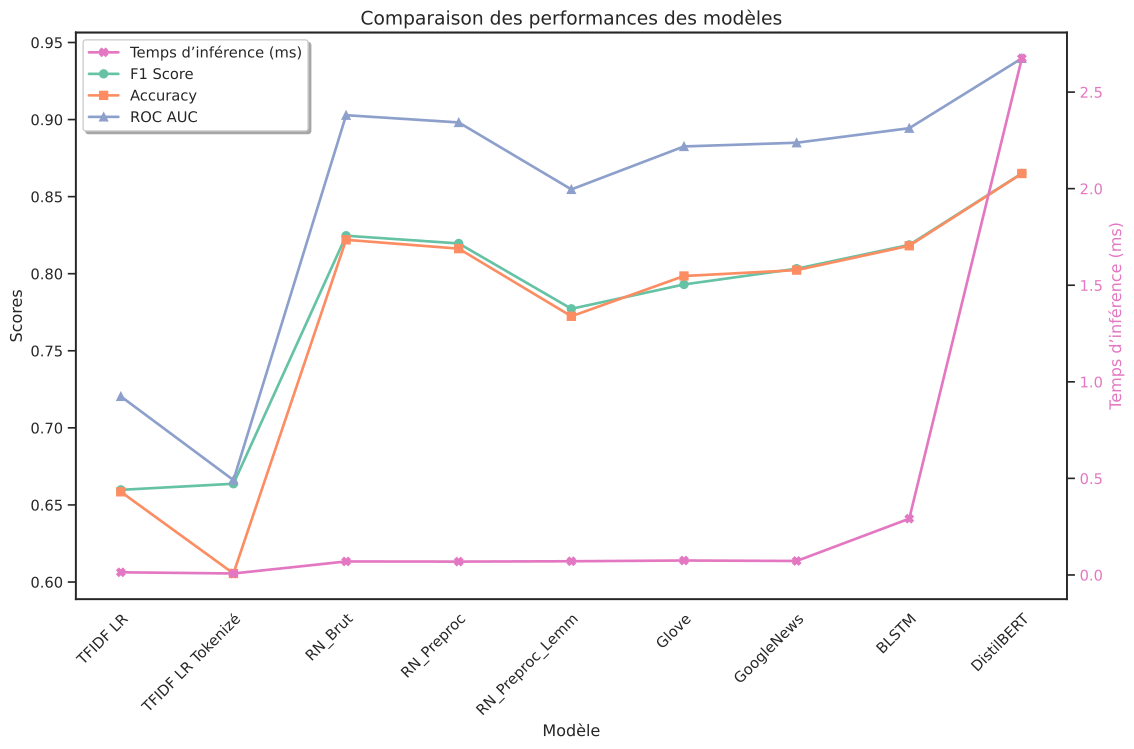
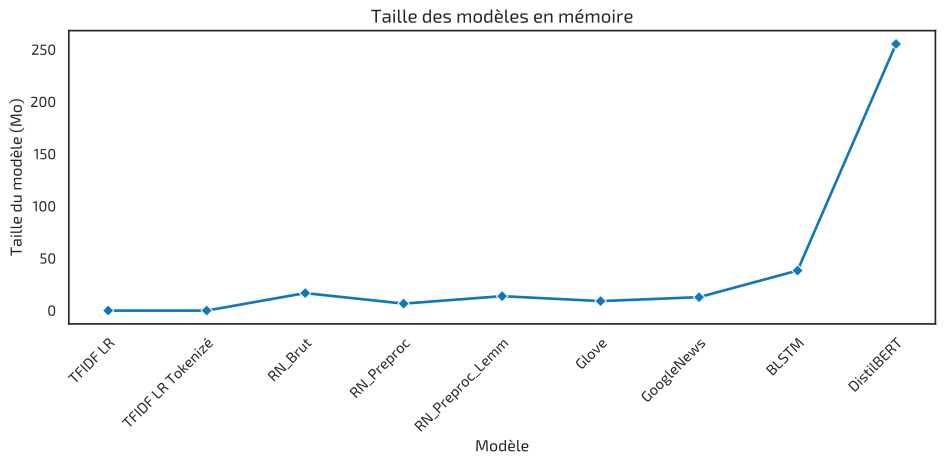
DistilBERT was ultimately selected thanks to its superior performance, ability to capture subtle linguistic patterns, and still reasonable model size for deployment. The second-best option was the raw RNN model without preprocessing.
Technical Deployment and API Automation
An API and UI were developed to ensure modularity and operational efficiency:
- Backend with FastAPI: handles prediction requests and returns predicted class along with probabilities.
- Frontend with Streamlit: interactive user interface including an alert feature allowing users to report misclassifications.
Both were containerized with Docker to guarantee portability and consistent execution across environments.
Automation and Continuous Deployment
GitHub was used for source code management, while GitHub Actions automated unit tests and Docker image creation. These images were then pushed to DockerHub before being automatically deployed to Azure, ensuring a robust CI/CD workflow.
Alerting System
Azure Insights complements the architecture by generating alerts when frequent incidents or repeated frontend error reports occur. In this example, three tweets reported as incorrectly classified within five minutes trigger an email and SMS alert to my inbox and phone.
Post-Deployment Monitoring
Recommended post-deployment actions for production usage include:
If alerts significantly increase, a human review of the data can be triggered to determine whether retraining is needed. A minimum threshold of 0.1% to 1% of the initial corpus (between 1,600 and 16,000 tweets) is defined to justify retraining.
Related posts
No related posts yet.