Semantic image segmentation applied to intelligent vision systems using urban scenes from the Cityscapes dataset.
Stack
Project links
The objective was to design, train, compare, and deploy deep learning models capable of assigning a semantic class to every pixel in an image, while balancing:
- segmentation accuracy,
- robustness,
- and inference performance.
The work covered:
- convolutional encoder–decoder architectures,
- advanced multi-scale models,
- a Transformer-based approach (SegFormer),
- as well as deployment through an API and an interactive web application.
Context & Objectives
Context
Semantic segmentation is a core task in computer vision, especially for:
- autonomous driving,
- urban scene analysis,
- intelligent transportation systems.
Unlike object detection, segmentation requires dense pixel-level predictions, which makes evaluation and deployment particularly sensitive to:
- class imbalance,
- boundary precision,
- inference latency.
Objectives
- Train and compare several segmentation architectures.
- Evaluate models using domain-relevant metrics (IoU, Dice).
- Measure trade-offs between accuracy and inference time.
- Deploy the best models through a REST API and an interactive application.
Dataset
| Element | Description |
|---|---|
| Dataset | Cityscapes |
| Images | Urban scenes |
| Classes | 8 semantic classes |
| Input Size | Resized and normalized RGB images |
| Split | Train / Validation / Test |
Project 8 — Baseline Models & Encoder–Decoder Architectures
Methodology
Project 8 aimed to establish strong baselines using convolutional encoder–decoder architectures.
Main steps:
- Data preprocessing and label encoding
- Data augmentation
- Model training
- Hyperparameter tuning
- Quantitative evaluation
Evaluated Models
| Architecture | Encoder | Description |
|---|---|---|
| U-Net | Custom | Baseline encoder–decoder |
| FPN | EfficientNet-B0 | Multi-scale feature aggregation |
| LinkNet | ResNet | Lightweight architecture with skip connections |
Training Setup
- Loss functions: Dice + Cross-Entropy
- Optimizers: Adam / AdamW
- Learning rate scheduling
- Data augmentation to improve generalization
Evaluation Metrics
| Metric | Purpose |
|---|---|
| IoU (Jaccard Index) | Overlap measurement |
| Dice Coefficient | Boundary-sensitive similarity |
| Inference Time | Production feasibility |
Key Results — Project 8
| Model | Mean IoU (Test) | Inference Time (relative) |
|---|---|---|
| U-Net (baseline) | ~0.69 | Fast |
| FPN + EfficientNet (no augmentation) | ~0.70 | Medium |
| FPN + EfficientNet (with augmentation) | ~0.81 | Medium |
| LinkNet | ~0.73 | Fast to medium |
Observations
- Data augmentation improved mean IoU by +10 to +12 points.
- FPN + EfficientNet offered the best accuracy / computational cost trade-off.
- U-Net remained robust but less effective on complex scenes.
_edited.jpg)
_edited.jpg)
Project 9 — Transformer-Based Segmentation (SegFormer)
Motivation
Convolutional architectures efficiently capture local patterns but may be limited when modeling global context.
Project 9 explored SegFormer, a Transformer-based architecture combining:
- local information,
- global dependencies,
- efficient multi-scale fusion.
Architecture Highlights
- Hierarchical Transformer encoder
- Multi-scale fusion
- Lightweight MLP decoder
- No fixed positional encoding
Training Strategy
| Element | Choice |
|---|---|
| Backbone | SegFormer B5 (pretrained on ADE20K) |
| Loss Function | Sparse Categorical Cross-Entropy + Dice / Tversky |
| Metric | Mean IoU |
| Optimizer | AdamW + scheduler |
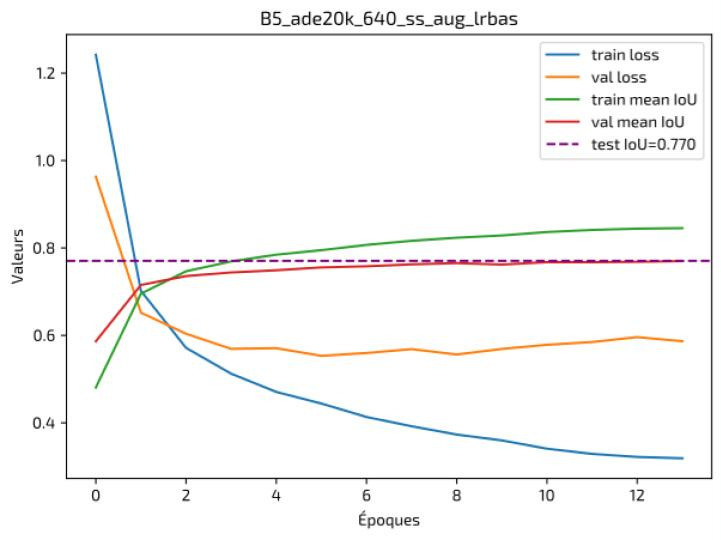
Results — Project 9
| Model | Mean IoU (Test) | Inference Time |
|---|---|---|
| FPN + EfficientNet | ~0.81 | Medium |
| SegFormer B5 | ~0.77–0.78 | Slower |
Interpretation
- SegFormer provided stronger global consistency on large structures.
- Competitive performance, but with higher computational cost.
- Well suited to scenarios where accuracy matters more than latency.
_edited.jpg)
Comparative Summary
| Model | Mean IoU | Strengths | Trade-offs |
|---|---|---|---|
| U-Net | ~0.69 | Simple, fast | Limited accuracy |
| FPN + EfficientNet | ~0.81 | Best overall balance | Moderate latency |
| SegFormer | ~0.77 | Global context | Higher cost |
Deployment & Application
API & Web Interface
- Backend: FastAPI
- Frontend: Streamlit
- Deployment: Containerized (Docker), cloud hosting
Features:
- Image upload
- Real-time inference
- Predicted mask visualization
- Class display
You can test the interactive demos of both projects below.
Special attention was given, for Project 9, to accessibility and clarity of the user interface.
Limitations & Future Work
Limitations
- Higher latency for Transformer-based models.
- Limited explainability for dense segmentation.
- Hardware constraints during training.
Future Work
- Model distillation
- Quantization / pruning
- Edge optimization
- Advanced production monitoring
Related posts
No related posts yet.