Segmentation sémantique d’images appliquée à des systèmes de vision intelligents, en utilisant des scènes urbaines issues du dataset Cityscapes.
Stack
Liens du projet
L’objectif était de concevoir, entraîner, comparer et déployer des modèles de deep learning capables d’assigner une classe sémantique à chaque pixel d’une image, tout en équilibrant :
- la précision de segmentation,
- la robustesse,
- et la performance en inférence.
Les travaux couvrent :
- des architectures convolutionnelles encoder–decoder,
- des modèles avancés multi-échelles,
- une approche basée sur Transformers (SegFormer),
- ainsi que le déploiement via API et application web interactive.
Contexte & Objectifs
Contexte
La segmentation sémantique est une tâche centrale en vision par ordinateur, notamment pour :
- la conduite autonome,
- l’analyse de scènes urbaines,
- les systèmes de transport intelligents.
Contrairement à la détection d’objets, la segmentation nécessite des prédictions denses au niveau pixel, ce qui rend l’évaluation et le déploiement particulièrement sensibles à :
- l’équilibre des classes,
- la précision des frontières,
- la latence en inférence.
Objectifs
- Entraîner et comparer plusieurs architectures de segmentation.
- Évaluer les modèles avec des métriques adaptées au domaine (IoU, Dice).
- Mesurer les compromis entre précision et temps d’inférence.
- Déployer les meilleurs modèles via une API REST et une application interactive.
Jeu de données
| Élément | Description |
|---|---|
| Dataset | Cityscapes |
| Images | Scènes urbaines |
| Classes | 8 classes sémantiques |
| Taille d’entrée | Images RGB redimensionnées et normalisées |
| Répartition | Train / Validation / Test |
Projet 8 — Modèles de Base & Architectures Encoder–Decoder
Méthodologie
Le Projet 8 visait à établir des baselines solides à l’aide d’architectures convolutionnelles encoder–decoder.
Étapes principales :
- Prétraitement des données et encodage des labels
- Augmentation de données
- Entraînement des modèles
- Ajustement des hyperparamètres
- Évaluation quantitative
Modèles évalués
| Architecture | Encodeur | Description |
|---|---|---|
| U-Net | Custom | Baseline encoder–decoder |
| FPN | EfficientNet-B0 | Agrégation multi-échelle |
| LinkNet | ResNet | Architecture légère avec skip connections |
Configuration d’entraînement
- Fonctions de perte : Dice + Cross-Entropy
- Optimiseurs : Adam / AdamW
- Scheduling du learning rate
- Augmentation de données pour améliorer la généralisation
Métriques d’évaluation
| Métrique | Objectif |
|---|---|
| IoU (Indice de Jaccard) | Mesure du chevauchement |
| Coefficient de Dice | Similarité sensible aux frontières |
| Temps d’inférence | Faisabilité en production |
Résultats clés — Projet 8
| Modèle | Mean IoU (Test) | Temps d’inférence (relatif) |
|---|---|---|
| U-Net (baseline) | ~0.69 | Rapide |
| FPN + EfficientNet (sans augmentation) | ~0.70 | Moyen |
| FPN + EfficientNet (avec augmentation) | ~0.81 | Moyen |
| LinkNet | ~0.73 | Rapide à moyen |
Observations
- L’augmentation de données a amélioré le mean IoU de +10 à +12 points.
- FPN + EfficientNet offre le meilleur compromis précision / coût computationnel.
- U-Net reste robuste mais moins performant sur scènes complexes.
_edited.jpg)
_edited.jpg)
Projet 9 — Segmentation basée sur Transformers (SegFormer)
Motivation
Les architectures convolutionnelles capturent efficacement les motifs locaux mais peuvent être limitées pour modéliser le contexte global.
Le Projet 9 explore SegFormer, une architecture basée sur Transformer permettant de combiner :
- informations locales,
- dépendances globales,
- fusion multi-échelle efficace.
Caractéristiques de l’architecture
- Encodeur Transformer hiérarchique
- Fusion multi-échelle
- Décodeur MLP léger
- Absence d’encodage positionnel fixe
Stratégie d’entraînement
| Élément | Choix |
|---|---|
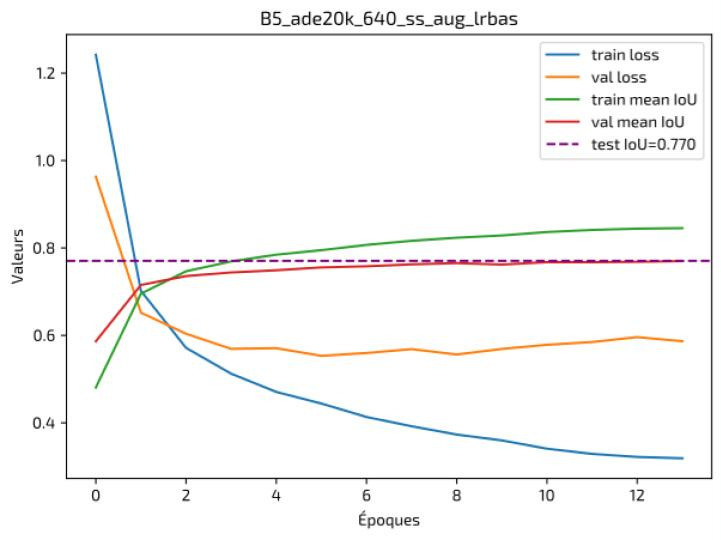
| Backbone | SegFormer B5 (pré-entraîné ADE20K) |
| Fonction de perte | Sparse Categorical Cross-Entropy + Dice / Tversky |
| Métrique | Mean IoU |
| Optimiseur | AdamW + scheduler |
Résultats — Projet 9
| Modèle | Mean IoU (Test) | Temps d’inférence |
|---|---|---|
| FPN + EfficientNet | ~0.81 | Moyen |
| SegFormer B5 | ~0.77–0.78 | Plus lent |
Interprétation
- SegFormer offre une meilleure cohérence globale sur grandes structures.
- Performance compétitive mais coût computationnel plus élevé.
- Approche adaptée aux scénarios où la précision prime sur la latence.
_edited.jpg)
Synthèse comparative
| Modèle | Mean IoU | Points forts | Compromis |
|---|---|---|---|
| U-Net | ~0.69 | Simple, rapide | Précision limitée |
| FPN + EfficientNet | ~0.81 | Meilleur compromis | Latence modérée |
| SegFormer | ~0.77 | Contexte global | Coût élevé |
Déploiement & Application
API & Interface Web
- Backend : FastAPI
- Frontend : Streamlit
- Déploiement : Conteneurisé (Docker), hébergement cloud
Fonctionnalités :
- Upload d’image
- Inférence en temps réel
- Visualisation masque prédictif
- Affichage des classes
Vous pouvez tester les démonstrations interactives des deux projets ci-dessous.
Une attention particulière a été portée, pour le Projet 9, à l’accessibilité et à la clarté de l’interface utilisateur.
Limites & Perspectives
Limites
- Latence plus élevée pour les modèles Transformer.
- Explicabilité limitée pour la segmentation dense.
- Contraintes matérielles pendant l’entraînement.
Perspectives
- Distillation de modèle
- Quantification / pruning
- Optimisation edge
- Monitoring avancé en production
Related posts
No related posts yet.